讀者剛聽到 CBOR時,也許覺得很陌生,難以理解。這邊快速解釋一下,讀者可以想象成,它就是一個類似 json encode 的函式庫,只是它編碼的方式是用二進位編碼,人眼無法直接解讀,但是效能比較好。
如果讀者仔細看原本的 Emacs 插件 裡,跟 CBOR 有關的部分,會發現:原本的 Emacs 插件裡,對於 CBOR 的部分,它的作法是複製、貼上某個 CBOR 函式庫的實作之後,再加以客製化。
當我在移植這個部分時,我傾向說:「如果可以的話,應該要讓 Conjure Piglet Client 直接依賴於 Lua 的 CBOR 函式庫。」像 Emacs 插件裡這種複製原始碼再修改的作法,無形中,會讓應用開發工程師 (application developer) 的認知壓力變得超大。
不料,我理想中的這種模組化移植法又比我想象中的困難多了。
在 websocket 打通了之後,我把訊息用 CBOR 編碼,送到 piglet 的 interpreter 去做 evaluation 。想不到,立刻失敗了。我在 Piglet 那端把 CBOR 編碼的結果用 cbor.me 網站來檢視一下,才了解失敗的原因。
問題出在:Piglet 期待的 CBOR 編碼,要在 keyword 之前,加上一個 tag 39。
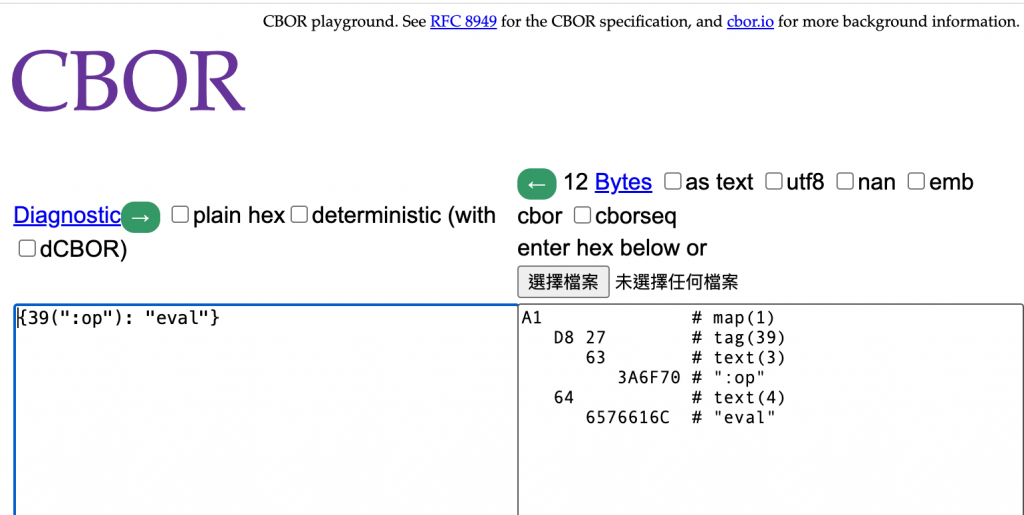
由於 spc476/CBOR 的 README 寫得相對精簡,再加上我對 Lua 很不熟,不熟到我連 setmetatable 都看不太懂。於是,我陷入了卡關:「到底要怎樣呼叫 Lua 的 cbor library,才有可能順利地插入 tag 39 且讓 tag 39 修飾 msg 裡的 keyword ?」
在開發過程之中,我問了 LLM 幾次,LLM 也給了幾種不同的呼叫法,都不正確。
我的 prompt 長成這樣子:
考慮使用以下的 lua library https://github.com/spc476/CBOR 希望 lua.encode({op = "eval"}) 的 hex 結果是 "a1 d8 27 63 3a 6f 70 64 65 76 61 6c" 即,希望插入一個 tag 39 用來修飾 op 這個 keyword 。 該如何呼叫 lua.encode ?
總之,後來,我捨棄了 LLM ,回頭慢慢去閱讀 README 和 Lua 的 API ,總算想出了解法。
(local cbor (require :org.conman.cbor))
;; 定義一個 keyword 函數,它可以用來註冊 __tocbor 函數
(fn keyword [s]
;; keyword changes the string $s => `:$s`
;; and return a table with the content is `{:v $changed_string}`
;; and the returned table has a `__tocbor` function in its metatable."
(let [t {:v (.. ":" s)}
mt {:__tocbor (fn [self]
(cbor.TAG._id self.v))}]
(setmetatable t mt)))
;; 宣告一個 msg,其中,它的 key 要用上面的函數修飾。
(local msg {(keyword "op") :eval (keyword "code") "(+ 1 1)"})
;; 將整個 msg 做 cbor 編碼,cbor.encode 會去呼叫 __tocbor 函數。
(cbor.encode msg)
在突破關卡之後,我重新設計了我的 prompt,在原本的 prompt 之後,附加上一段引導 LLM 思考的段落:
你在設法解這個問題時,請照以下的順序進行思考:
1. 欲使用之功能,是否可能是 spc476 函式庫的設計者最初沒有覆蓋到的情境?
2. 函式庫的設計者是否已經對這種情況,應用了鬆耦合機制,讓使用者日後可以做出修改?
3. Lua 語言,它的鬆耦合機制為何?
4. 綜合考慮 1, 2, 3 之後,該如何呼叫 lua.encode ?
當我使用這個新的 prompt 去請 LLM 示範函式庫的調用時,LLM 的產出,品質大幅提高。有的 LLM 甚至還成功了;就算是失敗的,也只差一步之遙了。
本篇提出了「結構化思考 prompt」的應用 AI 方式,可以說是受到 CBOR 編碼與 Piglet 預期格式不符的挑戰而催生的。
某種程度來講,這回解的問題也還是跟之前 day20, day21, day22 一樣是移植問題。但是它是「模組化移植」,我在移植的同時,還一邊去改善系統的模組化。
如果只要求快的話,也許一開始就暴力地讓 LLM 直接移植 Emacs 插件裡的 CBOR ,還比較快,因為說不定只靠 AI 即可完成,相對不需要人工的介入。
這就導出了一個矛盾的議題:「AI 善長簡單暴力的作法,而且也做得很快。但是,身為程式開發者的人類,有辦法一直跟不優雅的程式碼共存嗎?」

